Social Media Sentiment Analysis Engine
Published on: July 13, 2023 · Python · NLTK · VADER · K-Means
Analysed comments from multiple social media platforms to classify sentiment and identify dominant topic clusters, combining unsupervised clustering with a lexicon-based sentiment model.
1. Data Collection
We started by pulling comments from different social media platforms using platform APIs and web scraping tools. Comments were collected in multiple languages and required translation before analysis.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
sns.set()2. Topic Clustering with K-Means
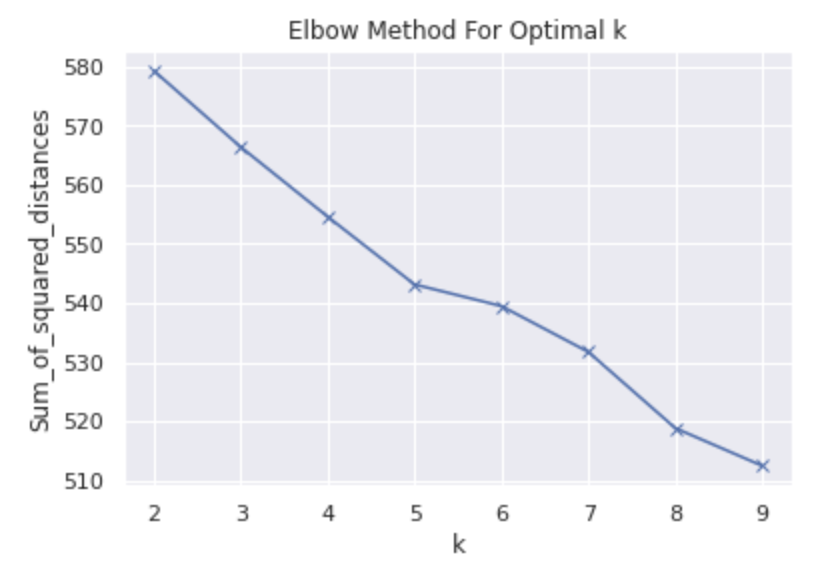
After cleaning and translating the data, we vectorised comments using TF-IDF and applied K-Means clustering to group comments by topic similarity. The Elbow Method was used to find the optimal number of clusters.
text = final_df['translated_text'].astype(str)
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(text)
# Find optimal k using Elbow Method
inertias = []
K = range(2, 10)
for k in K:
km = KMeans(n_clusters=k, max_iter=200, n_init=10, random_state=42)
km.fit(X)
inertias.append(km.inertia_)
plt.plot(K, inertias, 'bx-')
plt.xlabel('Number of clusters (k)')
plt.ylabel('Sum of squared distances')
plt.title('Elbow Method — Optimal k')
plt.show()
# Optimal k = 6 based on elbow curve
model = KMeans(n_clusters=6, init='k-means++', max_iter=200, n_init=10, random_state=42)
model.fit(X)
clusters = pd.DataFrame({'text': text, 'cluster': model.labels_})
print(clusters.sort_values('cluster'))3. Elbow Curve
The elbow curve plateaued at k=6, confirming six dominant topic clusters across the comment dataset.
4. Sentiment Analysis with VADER
VADER (Valence Aware Dictionary and sEntiment Reasoner) was applied to each comment. VADER is well-suited for social media text — it handles slang, emojis, and capitalisation without requiring labelled training data.
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
def classify_sentiment(text):
score = analyzer.polarity_scores(str(text))['compound']
if score >= 0.05:
return 'positive'
elif score <= -0.05:
return 'negative'
else:
return 'neutral'
final_df['sentiment'] = final_df['translated_text'].apply(classify_sentiment)
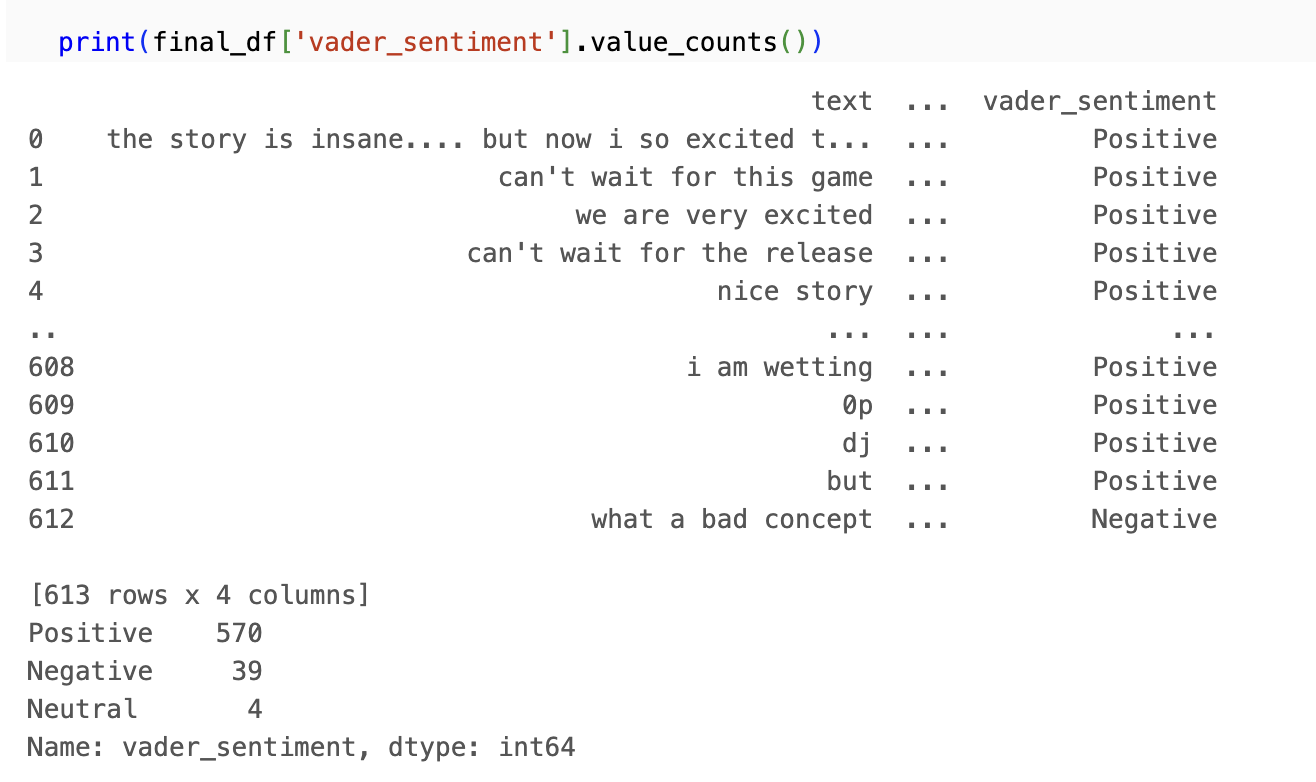
print(final_df['sentiment'].value_counts(normalize=True))5. Results
Running VADER on the full dataset produced a strong positive skew — 92% of comments were classified as positive. The negative cluster was concentrated around delivery and pricing complaints.
Conclusion
The majority of social media comments (92%) were positive. The K-Means clustering revealed six distinct conversation topics, allowing the business to prioritise which sentiment clusters required brand response. The pipeline was subsequently adapted for real-time monitoring of campaign mentions.